Knowledge Bytes | Local AI Models
2026-04-17
NVIDIA CUDA - Hardware Support
- RTX 40- and 50- series cards
- RTX 30- series still used in education
- 8GB - 32GB VRAM
- RTX 40- and 50- series laptops (although thermal throttled)

NVIDIA CUDA - Hardware Support

- DGX Spark
- Launched in 2025
- NVIDIA GB10 Blackwell GPU
- 128GB of unified memory
- 4TB NVMe SSD
- Well suited for fine-tuning open-source models
- Multiple vendors (MSI, ASUS, DELL)
AMD ROCm - Hardware Support
- RX70- and 90- series
- 8GB - 32GB VRAM
- Competitive prices compared to NVIDIA RTX
- But limited libraries compared to CUDA

AMD ROCm - Hardware Support

- Strix Halo
- Competitor to DGX Spark
- RX8060S and 128GB unified memory
- Price competitive
- Multiple vendors (HP, Corsair, Xiaomi)
Apple Silicon - Hardware Support
- Available on all M-series hardware
- Unified memory by default
- Up to 128GB on laptops and 512GB for the Mac Studio
- Non-portable models (MLX format)

Discovering Open-Source Models
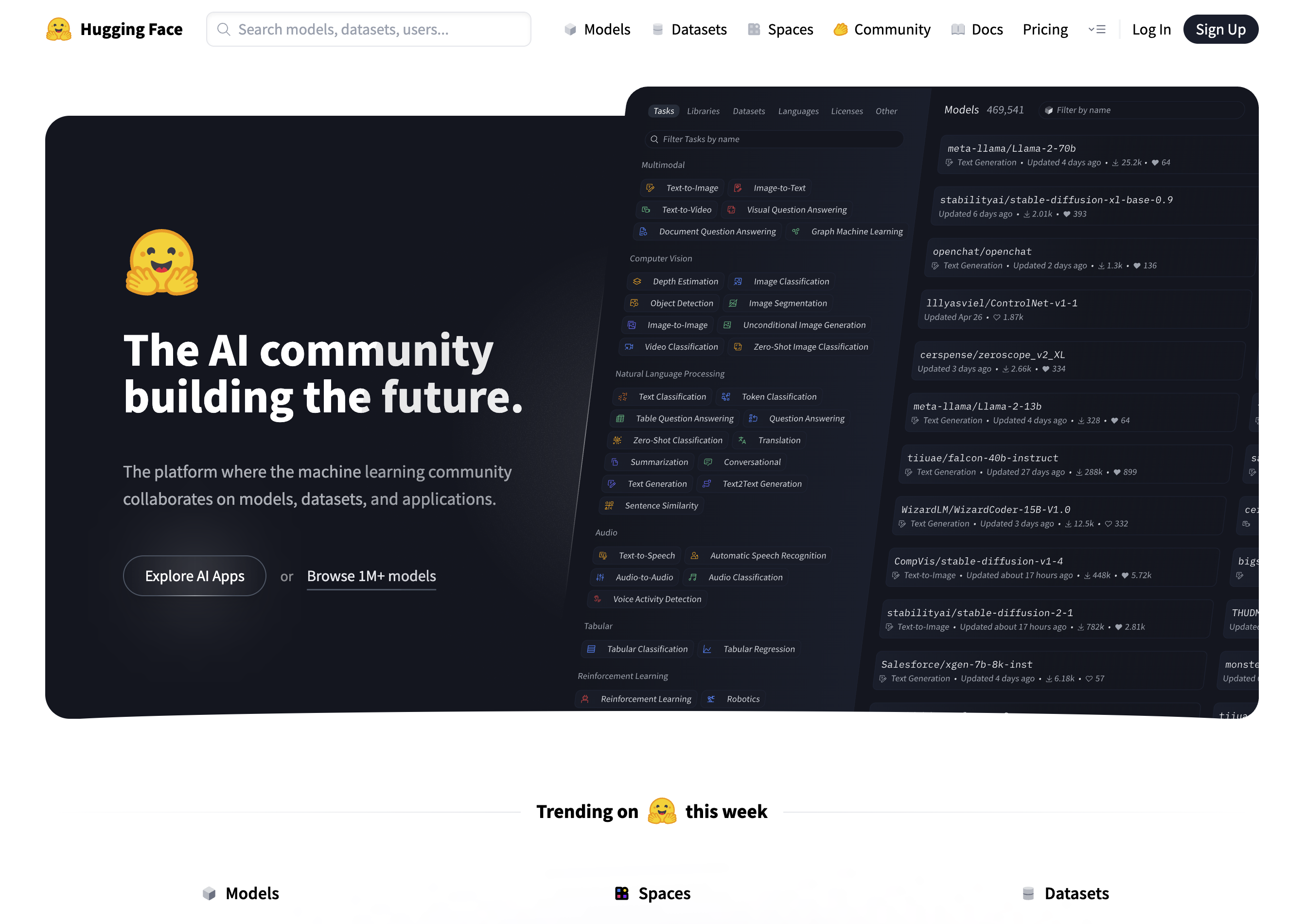
Source: https://huggingface.co
Let’s Visualize This!

Simulating 35B parameters at FP32 (9.38Mb)
Let’s Visualize This!

Simulating 27B parameters at FP32 (5.70Mb)
Let’s Visualize This!

Simulating 9B parameters at FP32 (1.90Mb)
Let’s Visualize This!

Simulating 4B parameters at FP32 (0.84Mb)
Let’s Visualize This!

Simulating 2B parameters at FP32 (0.41Mb)
Let’s Visualize This!

Simulating 0.8B parameters at FP32 (0.16Mb)
Let’s Visualize This!
Simulating 35B parameters at FP32 (9.38Mb)
Let’s Visualize This!

Simulating 35B parameters using Q8_0 (8-bit) Quantization (2.49Mb)
Let’s Visualize This!

Simulating 35B parameters using Q4_0 (4-bit) Quantization (1.32Mb)
Let’s Visualize This!

Simulating 35B parameters using Q2 (2-bit) Quantization (0.73Mb)